Tech & Review
The Backbone of Memory: A Deep Dive into Vector Databases and RAG Architecture
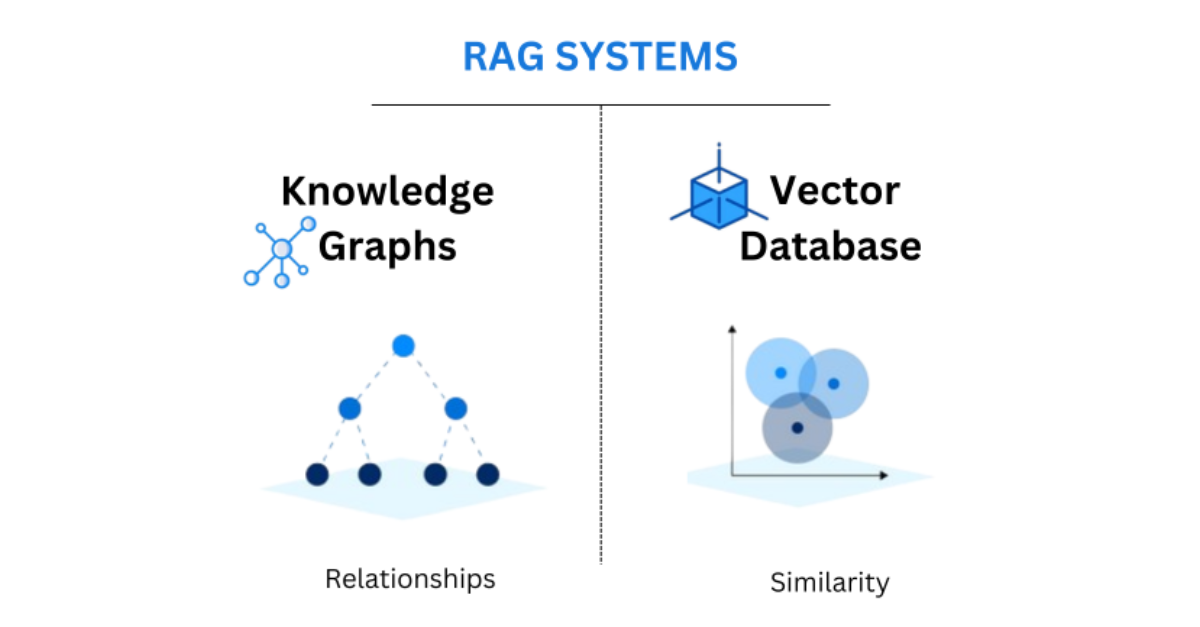
Solving the AI "Hallucination" ProblemOne of the most frequent topics in AI News at Scalexa is the refinement of Retrieval-Augmented Generation (RAG). While early AI models often suffered from "hallucinations"—confidently stating false information—modern RAG architectures solve this by connecting the LLM to a high-speed Vector Database like Pinecone, Milvus, or Weaviate. This allows the AI to "look up" facts in your company''s private documentation before generating an answer. For a technical agency like Scalexa, this means building support bots and internal search engines that are 100% accurate because they are grounded in real-time, verified data. The transition from general AI to "Context-Aware AI" is the single biggest factor in enterprise adoption today. By storing your data as high-dimensional vectors, you enable the AI to understand semantic relationships between concepts, rather than just matching keywords.Optimizing the Technical StackChoosing the right vector database is a critical decision for your tech stack. We have reviewed the performance of managed solutions versus self-hosted instances, and for high-volume e-commerce, the latency of your vector search is just as important as your page load speed. Scalexa specializes in optimizing these data pipelines, ensuring that your AI can retrieve the right information in milliseconds. As we move further into 2026, the ability to give your AI a "long-term memory" through advanced vector storage will be the differentiator between a simple chatbot and a true digital assistant. Stay tuned to Scalexa for more deep dives into the infrastructure powering the next generation of intelligent software.
AI Infrastructure: Leveraging private data for custom LLMs [interlink(13)] and the 2026 AI News roadmap [interlink(90)].
Read Article